
Tracking all the relevant publications on climate change has become impossible. Climate science and policy need a new approach for an age of big literature.
When the lines between scientific facts, legitimate disagreements and uncertainties about climate change are being deliberately blurred – not least by world leaders like Donald Trump and Recep Tayyip Erdoğan – the work of the Intergovernmental Panel on Climate Change (IPCC) has never been more important. It is the IPCC’s task to make sense of the landscape of scientific findings, where they agree, and why they may differ. The authors of the IPCC’s sixth assessment report – hundreds of scientists across many disciplines – have a massive task on their hands, ahead of its publication in 2021.
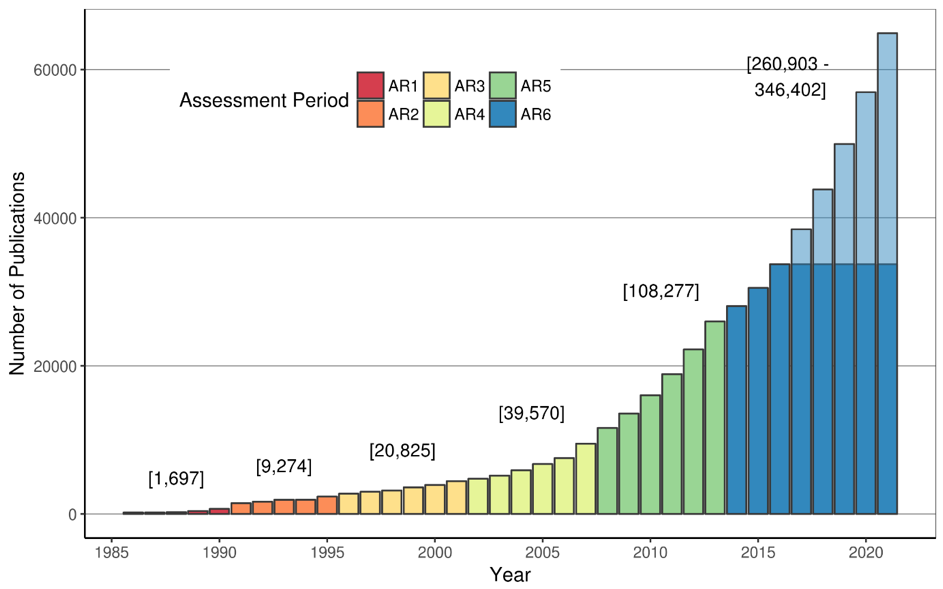
When the volume of scientific information continues to grow exponentially, so does the difficulty of maintaining a clear overview. Tracking and reading all of the relevant publications on climate change has become impossible, as more emerge in a single year than was previously the case over an entire, or multiple, assessment periods. Even if there was no further growth over the next three years, the relevant literature to be reviewed for the IPCC’s sixth assessment will be somewhere between 270,000 and 330,000 publications. This is larger than the entire climate change literature before 2014. So conducting a scientific assessment is increasingly a “big literature” challenge.
Managing the literature is vital if we are to ensure the credibility of the IPCC in future. We need to let computers help us to read and digest information we can no longer comprehend on our own.
The IPCC needs to lead the way towards a new era of computer-assisted assessments. Machine learning and natural language processing must be used to understand and synthesise a huge volume of relevant material. New categories of experts – from scientometrics, computational linguistics and data analytics – will need to be involved.
Decision-makers also want knowledge from the research community that can contribute to meaningful solutions. But systematic progress in learning about climate solutions has been limited within the IPCC to date. The quest to understand what policies work well – and under what conditions – remains in its infancy.
This problem is particularly acute in the social sciences. Some argue that social science evidence doesn’t lend itself to generalization. But a bigger challenge is the lack of appreciation for research synthesis as a scientific endeavor in its own right. The dearth of synthetic evidence in policy and social science literatures makes it impossible for the IPCC to aggregate the knowledge that is diffused across thousands of individual studies.
Changing the culture of the social sciences to better support scientific assessment and accumulated learning about climate change solutions won’t be easy. While the IPCC can act as a catalyst, any shift will also require more capacity in synthesis methods, and support for collaborative networks. Research funders and governments also need to direct more funding towards research synthesis.
The good news is that there are models for such a transformation. Researchers in medicine, education and psychology have been forced to grapple with similar challenges over recent decades –and systematic research synthesis is now well established within these fields as a basis for policy advice.
The misleading impression that any single scientific study has the same standing as all others is toxic for a culture of evidence-informed policymaking. By elevating research synthesis to the gold standard of scientific policy advice – and using big data and machine learning techniques to deliver it – we can strengthen the IPCC and provide a stronger response to the Trumps and Erdogans of this world, who want to cherry-pick evidence to suit their own agendas.
This article was originally published at The Guardian Science Blog.
